
摘 要:通过语义相关度进行搜索引擎的设计是一种有效途径,现通过分析搜索时获得的页面数和各页面的关键词密度,提出一种基于核函数的语义相关度算法。同时,在标准测试集上进行数据实验,并与其它几种已有方法对比,结果显示该方法与专家打分值的Spearman相关系数最高,进一步表明了该算法的有效性,由于新算法中使用的关键词没有词性、语法等限制,且算法简便,所以有利于实际应用和推广。
关键词:搜索引擎;语义相关度;核函数;关键词密度
中图分类号:TP391.41 文献标识码:A 文章编号:2096-4706(2018)09-0077-03
Abstract:It is an effective way to design search engine through semantic relevancy. By analyzing the number of pages obtained and the keyword density of each page,a semantic correlation algorithm based on kernel function is proposed. At the same time,the data experiment on the standard test set is carried out and compared with several other existing methods. The results show that the correlation coefficient of the method and the Spearman of the expert score is the highest,which further indicates the effectiveness of the algorithm. Because the key words used in the new algorithm are not restricted by parts of speech and grammar,and the algorithm is simple,it is conducive to practical application and promotion.
Keywords:search engine;semantic relatedness;kernel function;keywords density
0 引 言
随着“互联网+”时代的到来,信息资源数量激增,搜索引擎已成为获取信息的重要工具之一,这也必然会引起人们对搜索引擎的重视与研究。目前,搜索引擎研究的两个主要方面分别是搜索结果排序与评测,将语义相关度、相似度的工作融入到搜索引擎的工作中,会使其更精确、更智能[1]。
现有的语义相关度计算方法大致可分为传统的和基于网络百科全书的计算方法[2],如上下文向量方法[3],潜在语义分析(LSA)[4],显示语义分析(ESA)[5]都可以用于计算,但其大多依赖Wordnet、Hownet等语义词典或语料库,使得算法本身就存在局限性,如受数据噪声的影响较大[2]且不便于计算。基于搜索引擎算法的出现使得这部分问题得到有效缓解,李素建在QA系统中引入语义计算,通过词与词之间的相似度与相关度,算得语句间的相关度[6];陈海燕利用语义片段去除噪音,提出SRPMI算法[7];陈肖雨等提出基于Page Counts的相关度算法[1]。本文则在其研究的基础上,提出了一种基于核函数的算法。
1 基于核函数的语义相关度算法
1.1 基本原理
陈肖雨等[2]假设若两词在同一页面内出现,那么它们必然存在一定的相关性,在此假设下由搜索词语返回的页面数来计算两词的关联度大小(记为rel);刘胜久等[8]借鉴集合论中集合相似度的概念,也定义了一种根据搜索引擎返回的匹配结果进行计算的方法(记为Liu)。经过测试,这两种方法均取得了不错的效果。
核函数最早在1964年被Ajzerman等[10]引入到机器学习中,但是一直停留在理论层面,1992年,Boser等[11]将运用此技术将线性的支持向量机(SVMs)推广为非线性SVMs。此后,其在文本分类方面得到更广泛的应用。《统计学习方法》一书指出核函数是映射关系的内积,运算时不用考虑映射函数具体形式,有利于简化计算[9]。对文本来说,在一定程度上它可以反映两个输入数据x,y之间的相关性,更加侧重词语之间的相似性。本文在查阅相关文献[1]的基础上,提出一种基于核函数的改进算法,其流程如下:
(1)预处理。将一对查询词x,y放入搜索引擎中查询,得到返回的页面数(单个搜索和共同搜索),以及匹配的n篇页面文档。其中,查询时返回的文档数量是巨大的。基于多数人的查阅心理以及搜索引擎将网页链接排序时遵从相关度由高至低的假设,取n=10,且去除词数过少的页面(少于70词)。然后,将文档转化为文本向量,其方法是多样的,如TFIDF。闫英杰的关键词密度分布算法结合了词频法与查询偏重法[12],同样可以提取文档的特征。考虑到算法的简洁性,这里借用了关键词密度这一概念。关键词密度是关键词出现次数占页面总字节的比例,一般在2%-8%为宜。计算搜索x时返回的页面中对y的关键词密度,将其值作为该页面的文本向量vi,得一组值C(x)=(v1,v2,…,vn)。
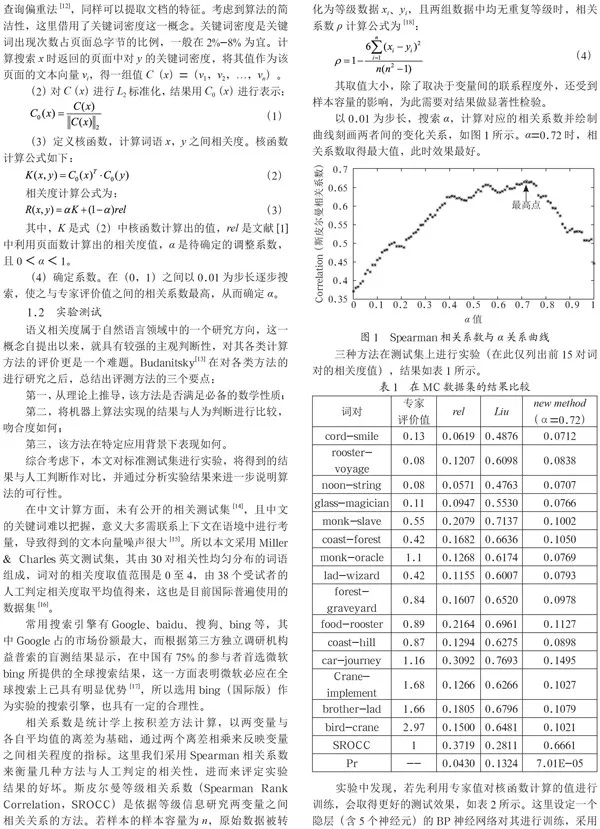
1.2 实验测试
语义相关度属于自然语言领域中的一个研究方向,这一概念自提出以来,就具有较强的主观判断性,对其各类计算方法的评价更是一个难题。Budanitsky[13]在对各类方法的进行研究之后,总结出评测方法的三个要点:
第一,从理论上推导,该方法是否满足必备的数学性质;
第二,将机器上算法实现的结果与人为判断进行比较,吻合度如何;
第三,该方法在特定应用背景下表现如何。
综合考虑下,本文对标准测试集进行实验,将得到的结果与人工判断作对比,并通过分析实验结果来进一步说明算法的可行性。
在中文计算方面,未有公开的相关测试集[14],且中文的关键词难以把握,意义大多需联系上下文在语境中进行考量,导致得到的文本向量噪声很大[15]。所以本文采用Miller Charles英文测试集,其由30对相关性均匀分布的词语组成,词对的相关度取值范围是0至4,由38个受试者的人工判定相关度取平均值得来,这也是目前国际普遍使用的数据集[16]。
常用搜索引擎有Google、baidu、搜狗、bing等,其中Google占的市场份额最大,而根据第三方独立调研机构益普索的盲测结果显示,在中国有75%的参与者首选微软bing所提供的全球搜索结果,这一方面表明微软必应在全球搜索上已具有明显优势[17],所以选用bing(国际版)作为实验的搜索引擎,也具有一定的合理性。
1.3 结果分析
从实验结果(表1)不难发现本文给出的方法(new method)符合认知,与原方法(rel)和另一种方法(Liu)相比,与专家值的相关系数SROCC达到0.6661,且Pr值远小于0.05,这从一定程度上说明该算法具有一定的优势和更强的有效性,改进后可引入到搜索引擎的工作中。经分析,其原因主要有以下几个方面:
(1)原方法实质上基于Page Counts,主要侧重的是词语之间关联程度的大小。而本文基于语义核函数,加入了对词语相似度的考量;
(2)本文在实际搜索过程中,已筛选出一部分无用网页,并进行了初步除噪。
其中,需要注意的是,无论使用何种搜索引擎,其网页信息都会处于实时动态更新维护中,这些将会使上述算法计算结果产生差异,但影响不大。
2 结 论
本文将已有的语义相关度算法简化,又将核函数融入其中,提出改进的基于搜索引擎的相关度算法,并在MC数据集上测试,测试结果与专家值的重合度较高,且相关系数有了明显的提高,说明该算法确实有效。后续加大数据集,对其进行训练,可达到更稳定的状态(表2),实际搜索时,将搜索词进行分词,与页面的关键词进行相关度分析,其结果可作为搜索引擎页面排序的依据。
同时,查询词通常带有语义信息,如今的搜索引擎大多还是采用基于关键词匹配的技术,而该技术的语义理解能力较弱,不能很好地把握用户意图[20]。该方法虽然在实验中的评测结果较原方法更优,但仍存在问题需要对其进一步优化和改进,以达到更高的要求。初步设想可以采用查询扩展法对关键词进行基于文本内容的适当的扩展,通过奇异值分解对词汇—文档矩阵进行降维,挖掘文档与文档间、词汇与文档间潜在的语义关系[21],再进行相关度的计算。
另外,中文分词词典规模庞大,一般在5万-25万词条之间[22],且同义词频繁出现,可能会导致同样的方法在中文测试集上的效果不明显。后续工作中应针对中文文本特性,作合理的调整,使之同样适用。
参考文献:
[1] 陈肖雨,郭雷,方俊.应用搜索引擎计算语义相关度的实现 [J].计算机工程与应用,2010,46(30):128-130.
[2] 游博.词语语义相关度计算研究 [D].武汉:华中师范大学,2013.
[3] Patwardhan S,Pedersen T. Using WordNet-based context vectors to estimate the semantic relatedness of concepts [C]//Proceedings of the EACL 2006 Workshop,Making Sense of Sense:Bringing Computational Linguistics and Psycholinguistics Together,Trento,Italy,2006,17(6):1-8.
[4] Dumais S T,Landauer T K. A solution to Platos problem:The latent semantic analysis theory of acquisition,induction and representation of knowledge [J].Psychological Review,1997,104(2):211-240.
[5] Gabrilovich E,Markovitch S.Computing semantic relatedness using Wikipedia-based explicit semantic analysis [C]//Proceedings of the 20th international joint conference on artificial intelligence,2007,6:1606-1611.
[6] 李素建.基于语义计算的语句相关度研究 [J].计算机工程与应用,2002(7):75-76+83.
[7] 陈海燕.基于搜索引擎的词汇语义相似度计算方法 [J].计算机科学,2015,42(1):261-267.
[8] 刘胜久,李天瑞,贾真,等.基于搜索引擎的相似度研究与应用 [J].计算机科学,2014,41(4):211-214.
[9] 李航.统计学习方法 [M].北京:清华大学出版社,2012.
[10] Ajzerman M A,Braverman E M,Rozonoehr L I. Theoretical foundations of the potential function method in pattern recognition learning [J].Automation and Remote Control,1964,25:821-837.
[11] Boser B E,Guyon I M,Vapnik V N. A training algorithm for optimal margin classifiers [C]//Proceedings of the Fifth Annual Workshop on Computational Learning Theory. New York:ACM Press,1992,5:144-152.
[12] 闫英杰,林鸿飞,杨志豪,等.关键词密度分布法在偏重摘要中的应用研究 [J].计算机工程,2007(16):156-158.
[13] BudanitskyA,Hirst G. Evaluating WordNet-based Measures of Lexical Semantic Relatedness [J].Computational Linguistics,2006,32(1):13-47.
[14] 汪祥.基于中文维基百科的语义相关度计算的研究与实现 [D].长沙:国防科学技术大学,2011.
[15] 万富强,吴云芳.基于中文维基百科的词语语义相关度计算 [J].中文信息学报,2013,27(6):31-37+109.
[16] 张波,陈宏朝,朱新华,等.基于多重继承与信息内容的知网词语相似度计算 [J].计算机应用研究,2018(10):1-2.
[17] “必应搜索·全球PK赛”中国正式启动 [OL].[2013-06-20].http://news.eastday.com/society/2013-06-20/346941.html.
[18] Spearmans rank correlation coefficient [OL].[2018-05-19].https://en.wikipedia.org/wiki/Spearmans_rank_correlation_coefficient.
[19] 胡金滨,唐旭清.人工神经网络的BP算法及其应用 [J].信息技术,2004(4):1-4.
[20] 王文斌.面向语义搜索的查询前置技术研究与实现 [D].上海:华东师范大学,2015.
[21] 王洋.基于潜在语义分析的智能搜索技术研究 [D].哈尔滨:哈尔滨工程大学,2010.
[22] 黄昌宁,高剑峰,李沐.对自动分词的反思 [C]//全国计算语言学联合学术会议,2003:26-38.
作者简介:陈倩(1997-),女,湖北黄石人,本科。研究方向:信息计算与处理;通信作者:唐旭清(1963-),男,教授,博士。研究方向:智能计算、生物信息学、生态系统建模与仿真。