
王科 丁倩梅 余万
摘 要:虚拟机热迁移技术是指可以把一个虚拟机从一台物理服务器迁移到另一台物理服务器上,整个过程虚拟机内部业务不中断,虚拟机热迁移大多是基于共享存储进行迁移,磁盘未使用热迁移技术。提出主要解决磁盘热迁移优化的算法及方案,主要适用于将虚拟机从一个存储载体以全量的形式热迁移至另一个存储载体,亦适用含有内存迁移的虚拟机整机迁移。通过算法将实现虚拟机的快速部署、快速动态分配等各种应用场景,达到节能降耗、负载均衡的目的。
关键词:COW;全量迁移;整机迁移
中图分类号:TP302;TP309.3 文献标识码:A 文章编号:2096-4706(2020)15-0104-04
Abstract:Virtual machine hot migration technology refers to that a virtual machine can be migrated from one physical server to another. The internal business of virtual machine is not interrupted in the whole process. Virtual machine hot migration is mostly based on shared storage,and the disk does not use hot migration technology. This paper puts forward the algorithm and scheme to solve the hot migration optimization of disk. It is mainly suitable for the hot migration of virtual machine from one storage carrier to another in the form of full quantity,and also suitable for the whole virtual machine migration with memory migration. Through the algorithm,various application scenarios such as rapid deployment and dynamic allocation of virtual machine will be realized to achieve the purpose of energy saving,consumption reduction and load balancing.
Keywords:COW;full disk migration;whole machine migration
0 引 言
近年来,虚拟化技术已经成为云数据中心大规模推广部署的核心技术。通过虚拟化技术将海量的底层基础计算、存储、网络资源等实例化一台独立的虚拟机器,而虚拟机迁移是数据中心的常见业务场景,虚拟机的迁移技术实现了虚拟机从一台物理机到另外一台物理机的迁移,使数据中心的资源配置更加灵活。一般虚拟机迁移技术分为冷迁移,即停机迁移;热迁移,即在线不停机迁移[1]。实际运用中常用到热迁移,虚拟机热迁移是虚拟化技术的重要组成部分,也是实现云计算中基础设施和服务的重要基础。笔者在日常教学科研中关注到国内外对虚拟机迁移技术的研究中磁盘部分许多采用增量快照的方案,这样效率高,耗时少,但存在一定的使用场景限制和速率瓶颈。而基于COW(Copy On Write,写时复制)双写(迁移过程中产生的动态数据同时写入源主机与目的主机)的虚拟机磁盘全量或整机迁移技术[2],在保证高效率、低耗时的情况下,主要针对优化虚拟机多磁盘全量迁移和整机迁移过程中存在可靠性、迁移速度、物理机额外开销等问题,适用于全量备份场景。
笔者在高校云计算平台的教学过程中,结合之前工作经验,因多次涉及各类迁移,发现非共享存储迁移很慢,通过教学实验测试得出通过热迁移可以极大地减少停机迁移的时间成本、服务成本开销,保障服务的连续性,提高了云数据中心资源的配置能力。经研究迁移原理后编写DEMO验证,并通过本文进行记录。
1 Xen预拷贝算法改进思路
1.1 改进可能存在的数据多次传输
通常磁盘迁移下的预拷贝算法,首先是将所有的数据块先拷贝至目的主机,然后由Bitmap记录脏数据块并进行迭代传输[3]。存在这样一种情况:涉及到内存迁移的情况时,内存迁移迭代的是每次传送在上次迭代中修改了的页,简称“脏页”。对于一些修改比较频繁的脏页,脏数据块产生时,其对应的数据块在第一次还未被拷贝至目的主机,若按照预拷贝算法[4],这个数据块位置的数据将被拷贝两次,也有可能在传输过程中多次被迁移,从而使整个传输过程传送的效率非常低。这些脏页又被称为“工作集”,工作集如果在传输中反复地被传送,会增加总迁移时间,所以需要一种策略去测定工作集,避免重复的传送造成的不必要消耗。
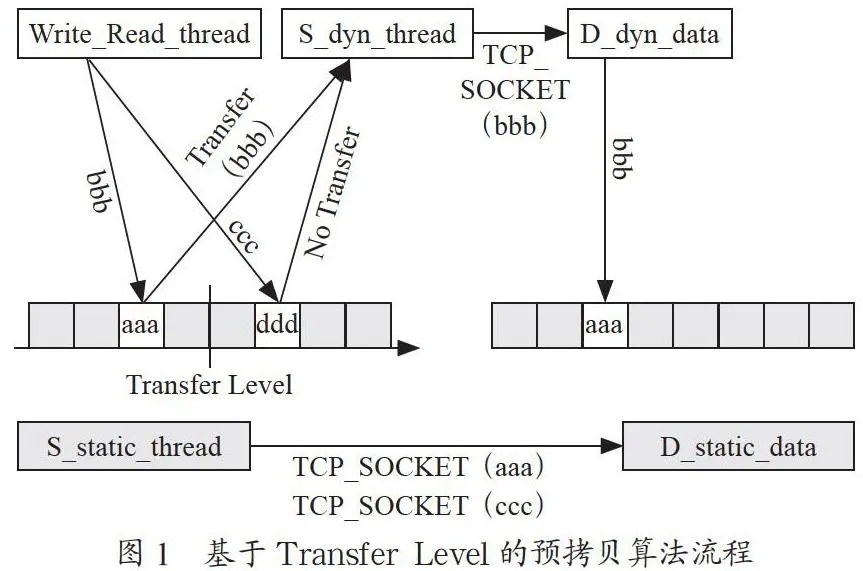
因此需要引入一个传输策略来控制数据的传输。提出引入传输水线(Transfer Level)对此种情况进行优化。水线是一个读进程锁,通过算法,将其用于记录传输静态数据块位置,位于水线之后的数据[5],无论Write_Read_thread怎么改动,其脏数据都不会被传送至目的虚拟机[6],而位于水线之前的数据在被Write_Read_thread改动后会立即被传输过去,如图1所示。其中aaa、ddd为内存对应位置原始数据;bbb、ccc为读写现场正写入的数据;S_dyn_thread源主机发送动态变化数据的线程;D_dyn_data目标主机接受动态变化数据的线程;S_static_thread源主机逐个发送动态静态数据的线程;D_static_data为目标主机接受静态数据的线程;TCP_SOCKET为tcp传输SCOKET。
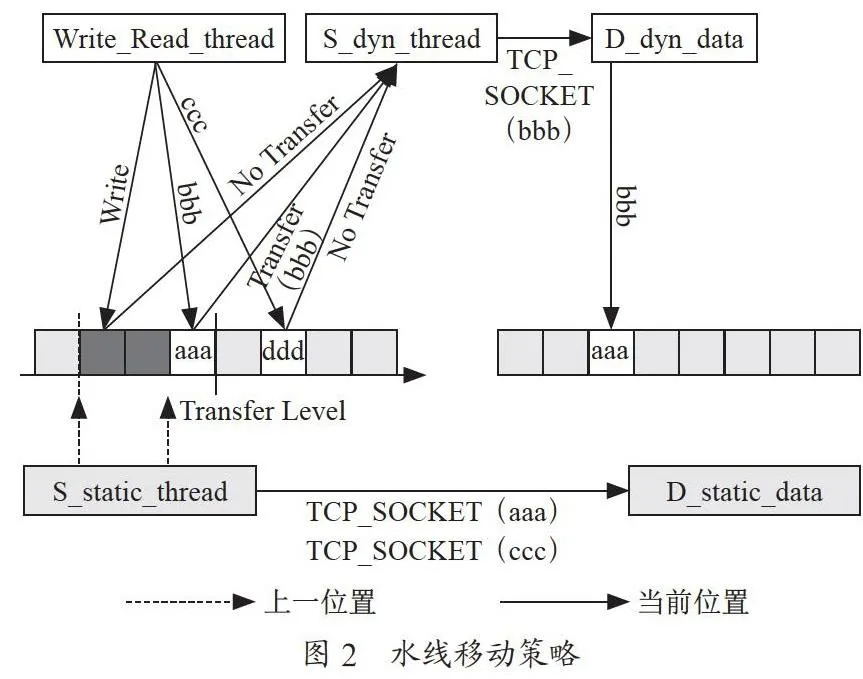
而其中水线的移动需要一个移动策略,来控制水线什么时候移动,以及每次移动位置实现什么功能。保证传输的优化效率达到最高。但制定此策略前需要对动态数据的写入情况进行一个位置的判定,这里我们在开始传输前结合Linux虚拟机的Ext4文件系统VHD的写入规则对新数据的位置进行判断[7]。
我们将磁盘大小的5%预留作为不被传输的区块,且这5%的区块是大量新数据即将写入的区块,如图2所示。
当水线(图2中虚线)移动到预留区块(图2中虚线箭头中间区域)首部时,水线直接跳过预留区块至其尾部,然后再正常移动。在水线移动到图中实线位置时,按照水线之前的数据(不包括预留区块中的数据)在被Write_Read_thread改动后会被立即传输至目的虚拟机,位于水线之后的数据,无论Write_Read_thread怎么改动,其脏数据都不会被传送的方法进行传输。当磁盘全量迁移完成进入双写阶段,即水线位于传输队列尾部时,水线回移到预留区块的首部,此时解除预留区块不被传输的属性,恢复正常的传输,水线正常移动,水线之前的脏数据保持双写,而水线之后至预留区块尾部之间的数据保持不被传输,水线正常移动至预留区块尾部时,若此刻水线之后还有相应预留区块,则水线移到此预留区块的首部重复上述过程。若此刻水线之后不存在相应的预留区块,则水线移到传输队列尾部,此时保持水线之前数据的双写,等待内存迁移。
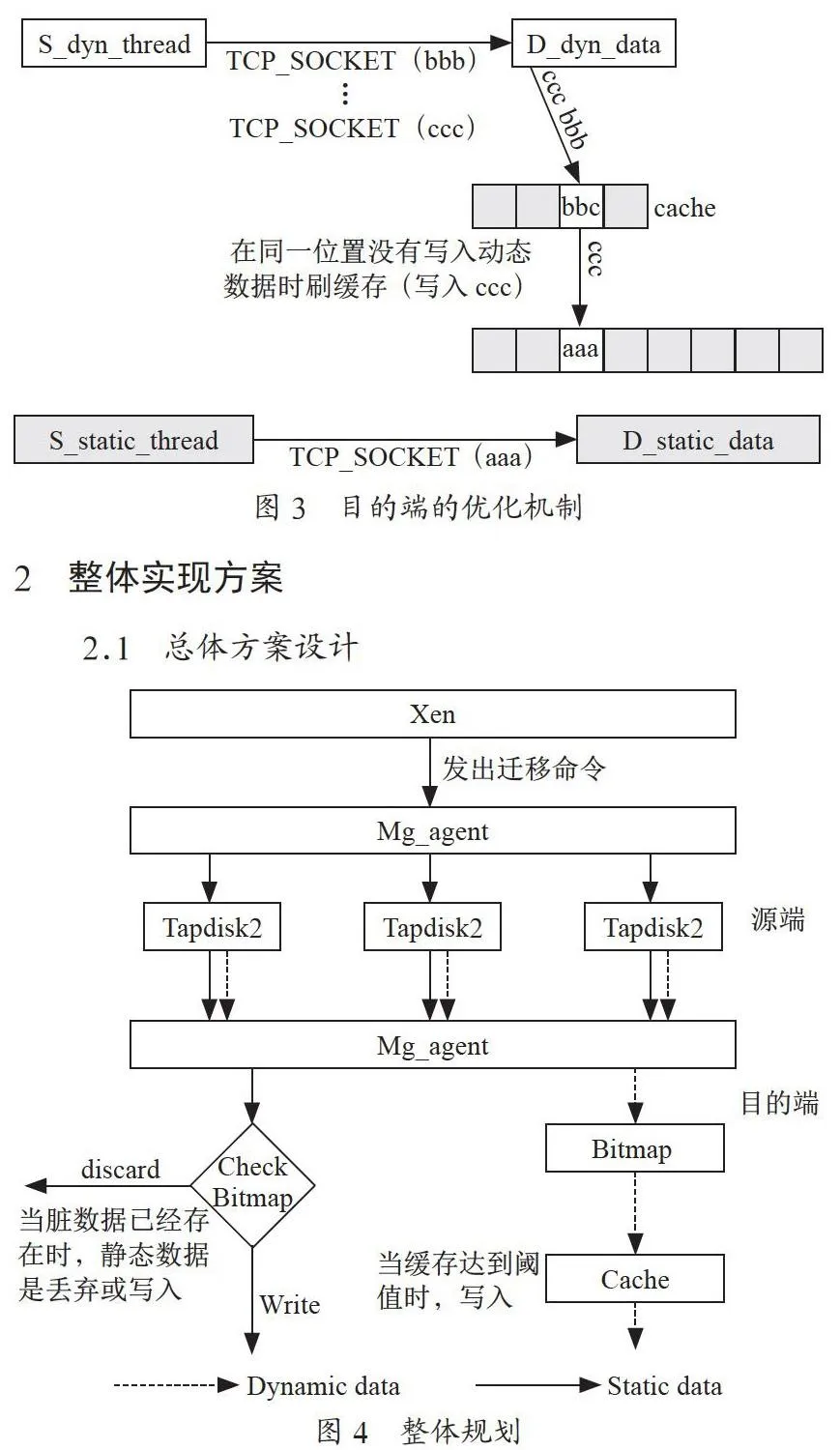
1.2 目的主机可能存在的数据多次写入
磁盘迁移下的预拷贝算法[8],第一步是将所有的数据块先拷贝至目的主机,然后记录脏数据块并进行迭代传输。存在这样一种情况:不在同一个传输周期内同一数据块位置变脏的时候,该数据块位置的数据将多次被传输至目的主机,目的主机将多次写入。对于磁盘迁移的情况,将多次产生磁盘I/O。提出在目的主机引入缓存对此种情况进行优化,如图3所示。
2 整体实现方案
2.1 总体方案设计
方案中迁移前资源检查、其他设备的迁移等方案保持与现有系统一致,改进方案只针对磁盘迁移相关模块。提出的改进方案支持一个虚拟机多个磁盘的全量迁移,亦支持一个虚拟机多个磁盘全量整机迁移(含内存迁移)。实现流程如图4所示[9]。
(1)源端Xen向Mg_agent模块下发磁盘迁移命令(含迁移相关信息);
(2)源端Mg_agent从Xenstore中读取源磁盘信息;
(3)源端Mg_agent向各个对应的Tapdisk2进程发送信号;
(4)源端Tapdisk2开始磁盘全量迁移流程,在磁盘Block写入处打开动态数据判断及动态数据传输流程;
(5)目的端Mg_agent收到源端发送的静态数据、动态数据;
(6)目的端收到的动态数据采用Bitmap记录,并缓存,达到阈值再写入磁盘;
(7)目的端收到静态数据后判断动态数据的Bitmap是否有脏位(解决临界数据可能出现的传输到达先后问题),决定是否写入目的磁盘。
2.2 引入Mg_agent进行多磁盘迁移的控制
2.2.1 对于不同主机多个磁盘全量迁移的情况
由引入的Mg_agent模块进行协调,其同时启动磁盘全量迁移,先完成数据传输的磁盘保持双写状态,等待其他磁盘完成,之后完成的磁盘也保持双写,等待剩余磁盘的数据传输。[10]流程如图5所示。
2.2.2 对于不同主机多个磁盘全量整机迁移(含内存迁移)的情况
在Xen模块中sleep_vm()前触发引入的Mg_agent模块进行磁盘全量整机迁移(含内存迁移),即,当磁盘全量迁移完成进入双写阶段后开始内存迁移[11]。流程如图6所示。
2.2.3 对于在同一台主机,不同存储设备之间磁盘全量迁移的情况
Mg_agent模块不用将静态数据与缓存的动态数据通过TCP_SOCKET发送至目的主机,而是直接写入目的存储设备[12],即,将发送至网络替换为写入目的存储设备。流程如图7所示。
3 方案测试和分析
3.1 实验目的
通过本方案[13]的优化算法及措施,在Xen平台上实现虚拟机的热迁移,在10 GB磁盘、20 GB磁盘、50 GB磁盘、100 GB磁盘大小并分别在1 GB、2 GB、3 GB、5 GB动态数据写入量的情况下测出数据包优化前的实际传输量以及优化后的传输量。
3.2 实验数据分析
从表1可知,优化方案基于以下两个方向进行优化:一是磁盘大小;二是迁移期间数据写入量。当磁盘大小一致时,数据写入量越大,优化方案优化效率越低,反之越高,甚至优化后写入数据传输量可以为零。当写入数据大小一致时,磁盘越大,优化方案优化效率越高,甚至磁盘在足够大的情况下优化后可以实现写入数据的传输为零。
4 结 论
本文通过对现有动态迁移机制的研究和分析,将传输水线思想引入拷贝策略当中,在一定程度上减少了实际迁移磁盘Block的数量和迁移时间。下一步将继续研究通过预测磁盘Block的改变概率,分批次对文中提及的静态数据进行拷贝,进一步降低重复拷贝的可能性,进而更进一步优化传输。
参考文献:
[1] 高翔.基于Xen的虚拟机动态迁移算法优化 [D].哈尔滨:哈尔滨工业大学,2010.
[2] 刘鎏,虞红芳,郑少平.面向业务动态变化的虚拟机迁移技术研究 [J].计算机应用研究,2016,33(2):534-539.
[3] 刘诗海,孙宇清,石维琪,等.面向可扩展集群环境的快速虚拟机迁移方法 [J].东南大学学报(自然科学版),2011,41(3):468-472.
[4] 郑婷婷,武延军,贺也平.云计算环境下的虚拟机快速克隆技术 [J].计算机工程与应用,2011,47(13):63-67.
[5] 常德成,徐高潮.虚拟机动态迁移方法 [J].计算机应用研究,2013,30(4):971-976.
[6] 周晨.云计算中面向能耗的虚拟机迁移研究 [D].南京:南京邮电大学,2016.
[7] 刘海坤.虚拟机在线迁移性能优化关键技术研究 [D].武汉:华中科技大学,2012.
[8] CLARK C,FRASER K,HAND S,et al. Live migration of virtual machines [C]//NSDI05:Proceedings of the 2nd conference on Symposium on Networked Systems Design & Implementation. Berkeley,CA,United States:USENIX Association,2005:273-286.
[9] CHAGANTI P. Xen Virtualization:A fast and practical guide to supporting multiple operating systems with the Xen hypervisor [M].Birmingham,UK:Packt Publishing,2007.
[10] 周煜,卢正添,易固武,等.一种基于过滤驱动的写时拷贝快照方法 [J].四川大学学报(自然科学版),2010,47(3):478-482.
[11] LIU H K,JIN H,LIAO X F,et al. Live migration of virtual machine based on full system trace and replay [C]//HPDC09:Proceedings of the 18th ACM international symposium on High performance distributed computing,New York,NY,United States:ACM,2009.
[12] 陈彬,肖侬,蔡志平,等.基于优化的COW虚拟块设备的虚拟机按需部署机制 [J].计算机学报,2009,32(10):1915-1926.
[13] 何玫峻,金连文,李磊.基于混合迁移的OpenStack虚拟机在线迁移改进方案 [J].系统工程理论与实践,2014,34(s1):216-220.
作者简介:王科(1985—),男,汉族,四川成都人,讲师,硕士研究生,研究方向:云计算、大数据。