
李学林 赵冬梅 梁明秀

摘 要:音素分割是语音研究的一个主要组成部分,在大词汇量连续语音识别及语音合成的过程中起着重要的作用。文章以贵州省中部苗语作为研究对象,对其进行特征的提取和音素边界划分。通过对录音的频谱能量进行低频、中频和高频的均值计算,找到各个频段均值点组成的波形突变点作为边界,去掉宽度低于20 ms的边界,然后将得到的边界点进行排序,再一次筛选出宽度大于20 ms的边界,得出划分的边界点。在一定的容错范围内,准确率能够达到83%。
关键词:苗族语音;Praat标注;语谱能量;语音分割
中图分类号:TN912 文献标识码:A 文章编号:2096-4706(2020)03-0019-03
Abstract:Phoneme segmentation is a main components of speech research,it plays an important role in large vocabulary continuous speech recognition and speech synthesis. In this paper,Miao language in the middle of Guizhou Province is taken as the research object,and its feature extraction and phoneme boundary division are carried out. The mean value of low frequency,intermediate frequency and high frequency is calculated through the spectrum energy of recording. Find the wave mutation point composed of the mean points of each frequency band as the boundary and remove boundary with width less than 20 ms. Then the boundary points are sorted,and the boundary points with a width of more than 20 ms are screened out again to get the boundary points. The accuracy can reach 83% in a certain range of fault tolerance.
Keywords:Miao nationalitys voice;Praat annotation;spectrogram energy;speech segmentation
0 引 言
贵州省作为少数民族大省,少数民族的类别比较多,经过长期形成的语言也比较多,但对其在语音识别领域的研究还未深入。这其中一个重要的原因是没有相应的数据库为我省少数民族语言识别的研究提供素材。我校属于少数民族院校,有相应的学科对地方少数民族语音进行研究和收集,少数民族语音素材丰富。在传统的语音建库中,一般是让专业人员通过手工的方法进行音素标注。但这种方法往往存在工作量大、对人员的专业性要求高、个体差异大、工作周期长的缺点,给音素级的标注带来了困难。特别是对于贵州省苗语等少数民族语言,由于缺乏相关的研究人员,利用手工标注的方法建立语音合成语料库变得更为困难。因此,可以根据语音识别中的强制对齐方法,利用Viterbi算法来自动获得语音的合成基元的时间标注,但这种方法仍然需要一个手工标注过的语料库训练语音识别所需的声学模型。[1]对于缺乏专业标注人员的贵州省苗语来说,会造成训练数据不足。
在当前语音研究领域,国内除了部分特殊部门或者公司有语音标注软件之外,现在大多还是使用Praat软件来完成语音的标注工作[2]。Praat软件功能比较强大,能够实现语音分析中各种参数的提取及输出,也可以通过编写脚本程序实现语音的特性分析,但在音素级标注方面依然需要大量的人工完成。构建大规模语音库是语音系统的主要任务之一,标注的规范性和精度是决定语音库质量的关键[3]。大量的语音数据标注需要许多的人力和物力,而且每个人对同一个音节的边界划分敏感度不同,产生的误差较大[4]。因此设计一种音素标注方法来解决个人因素造成的影响显得尤为必要。
本文设计的语音边界划分方法能提高音素标注的效率,统一相同音素的划分精度,再通过人工对少量有问题的音素划分进行校准,实现缩小误差和减少错误现象。因此设计一种高精度的音素时长边界划分,对语音音素级的标注起着重要的作用。
1 贵州中部苗族语音特征
贵州省苗族语言大致分为中部、东部和西部三个部分。本文主要以中部苗族语言为研究对象(既黔东方言),由北部土语、东部土语、南部土语3个部分组成,没有带鼻冠音的塞音、塞擦昔声母,没有连读变调现象,其中声母32个、韵母26个、声调8个。
对10个来自贵州省中部苗语地区的同学的录音材料进行采样、整理、纠错、标注工作。录音环境选在安静的教室中进行,使用常规笔记本电脑,录音软件为斐风,采样率为44.1 KHz,精度为16 bit,单通道,共采集2 000个左右常用词汇。因为并非专业录音环境,可能存在一定的噪音,与专业录音相比存在一定的偏差。语音音素边界划分及标注采用Praat软件进行,采用国际音标进行标注。
通过对采集到的语音数据进行观察,将语谱图能量图形状和音素边界相结合,把语音的语谱能量在所有频率区域分为两类,开口型和非开口型。这里从众多词汇当中筛选出两个典型的发音展示,分别为翻译成汉语的“蛊”和“八哥”,使用Praat打开观察其特征情况。部分发音类型语谱图如图1所示,图最上面为原始语音数据波形,中间是语谱图,其中黑色的部分代表能量,颜色越深,能量越大,最下面是使用人工标注的音素,其中sil表示静音段,最终用蓝色的竖线分开两个音素,从而得到各个音素边界点的时刻。
图1(a)为带有开口型的语谱图,从图中可以看出,在中频部分,音素的能量呈现一定的变化,其中多含有音素为a的元音或者相近的发音,且含有送气音,能量较大的部分在时间轴上呈现一定开口形状。图1(b)语谱能量在低频(0 kHz~1 kHz)、中频(1 kHz~2.5 kHz)和高频(2.5 kHz~5 kHz)区域相对比较规律,随着时间轴具有明显能量突变划分点,称为非开口型。通过大量的观察比对,发现贵州省中部苗语语谱图形状多为这两种情况的组合。
频谱能量为开口型的音素,对依靠能量变化来进行音素边界标定具有一定的迷惑作用,容易在中频部分造成多分的情况,送气音能量较低,易造成漏分的情况。
2 语音音素分割
本文音素边界检测主要依靠语谱能量突变换作为划分依据,用两个步骤来完成。第一,对整个语音的语谱能量进行区域划分,并进行均值计算,得到对应的波形图;第二,根据得到的能量均值波形图,设定阈值,切掉下半部分,将有波形数据的点作为每个区域的音素边界,并进行宽度筛选,将各个区域的边界数据融合,然后再次在时间轴上进行筛查。最后得到音素边界的时刻点。
2.1 音素边界检测
语音信号是一种时变信号,长时区间不具备稳定性。但在短时区间下,其波形基本保持稳定,这个时间长短在10 ms至30 ms的区间,为了使分割的数据更加细致,这里取6 ms为一帧。因此对语音信号的处理和分析大多在短时的基础上。同一音素的两帧之间,语谱能量值不会发生巨变。因此将能量值在低频、中频、高频3个区域进行均值计算,得出均值组成的波形曲线,分别得出语音在3个区域的变化波形。波形出现聚变的地方,认为是两个音素的边界。
2.2 音素边界筛选
在进行分区域检测边界时,因为每个区域的频谱能量有所区别,因此需要设不同的阈值,以便提高分割的准确性。通过大量实验,在低频区域取中心点大于0.4为阈值点,中频区域也取0.4,高频区域取0.25。为了避免出现两条边界时长过短的现象,需筛选相邻边界线的时长间距至少大于20 ms,以滤掉短时过冲情况。
在分割出各个区域的音素边界点后,将各个区域的分割数据合并,并按照从大到小进行排序,筛选出所有大于0的数据,取出边界点间宽度大于20 ms的数据作为分界点。最终得到音素的边界时刻数据。
2.3 结果评定
这里假定人工标注的时长数据为标准数据,通过比较边界检测算法得到的时长与人工标记的音素边界时长的距离来评价检测算法的性能。假定容错时间差为t(ms),如果检测结果与人工标注边界的距离在t(ms)内,则正确检测到该音素边界;若在容错时间范围内得到n个边界值,则多的n-1个值为错误检测;若容错时间内没有检测到对应的边界,则认为出现漏分。[5]
3 实验结果
3.1 实验
实验数据是收集的贵州省中部苗语词汇2000个左右,基本覆盖了中部苗语的日常用语范围。人工使用Praat进行音素级标注,经过检查、校验,认为人工分割的音素为标准数据,可以作为算法检测边界正确性的参照。
边界检测在与人工标注的数据进行对比后,若容错范围在20 ms的时候,正确率为67.9%;若容错范围在30 ms的时候,正确率为75.4%;若容错范围在40 ms的时候,正确率为83%。
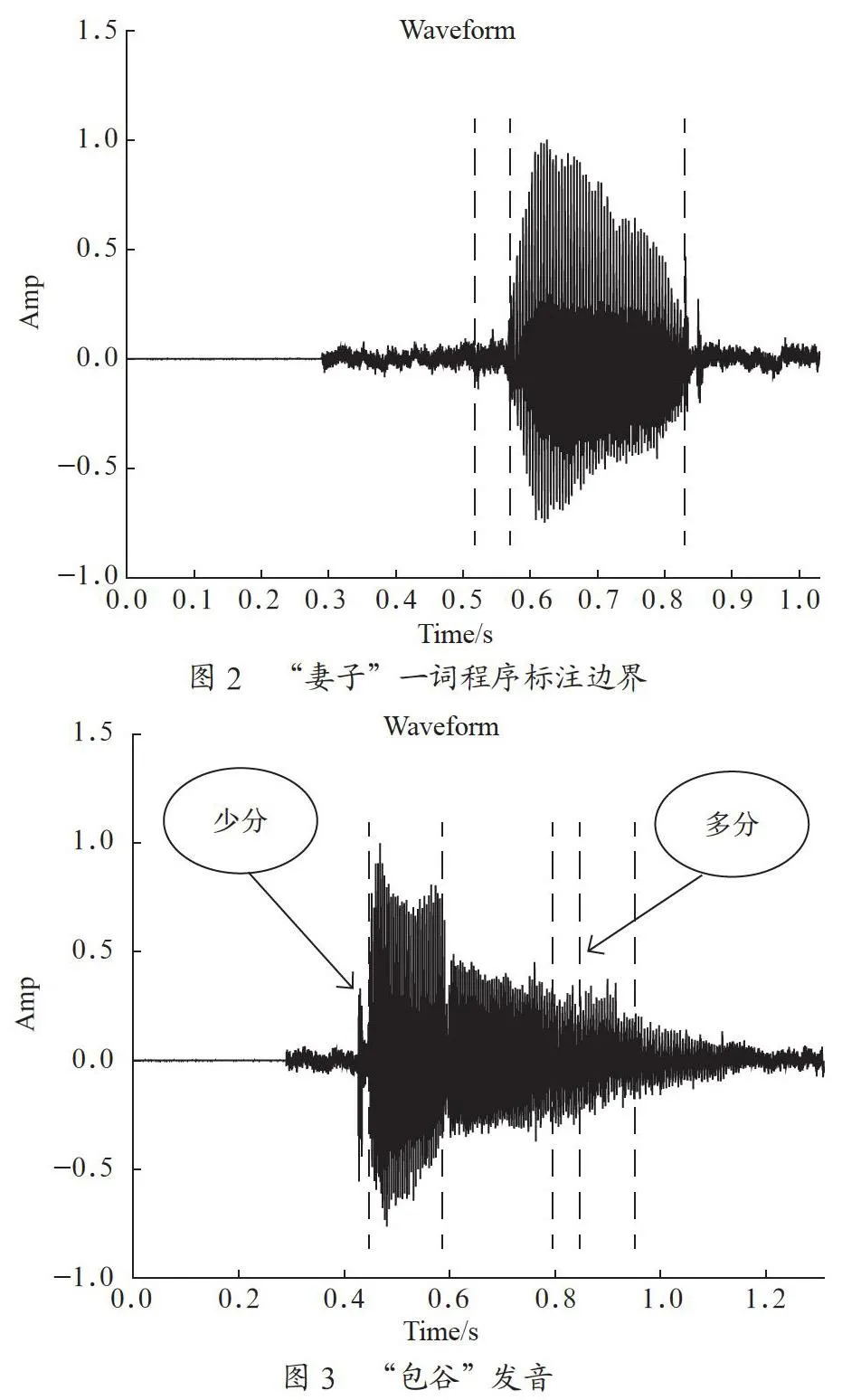
下面以“妻子”这个词为例,“妻子”一词程序标注边界如图2所示,在与人工使用Praat标注的边界时刻比较,边界检测程序计算的时刻在容差范围内。
3.2 实验分析
与人工划分相比,本实验方法的划分准确性还需提高,仍然存在漏分的现象。主要是贵州省中部苗语的元音发音在频谱能量上表现呈现一定开口等分布不均匀的情况,造成虽然是一个音素,但是中间能量分布不均匀,变化过大,超过阈值区间,造成误分或者漏分。送气音由于能量过低,造成均值的值过小,低于设定的阈值,造成漏分。“包谷”发音如图3所示,右边由于频谱能量呈开口型,造成数据的交叉,最终合并后,造成多分的情况,左边由于送气音能量过低,造成漏分的情况。
4 结 论
本文根据贵州中部苗族语音的语谱能量特点,设计了一种边界检测的算法。此方法将语谱能量按频率分布分成3个区域,分别为低频、中频和高频,在每个区域内进行均值计算,因为相同音素相邻两帧的能量变化不会出现突变,各个区域的均值数据在时间轴上不会突然跳跃。因此把每个区域均值突变的地方当成两个不同音素的边界,然后进行数据合并,把不能重合的数据进行筛选合并,最后得出整个语音的边界。通过实验证明,该方法针对贵州省中部苗族语音音素边界划分具有良好的效果。
参考文献:
[1] 刘豫军,夏聪.语音合成音库自动标注方法研究 [J].网络安全技术与应用,2015(2):65-66.
[2] 杨艳珍.语音半自动标注系统的设计与实现 [D].兰州:西北师范大学,2015.
[3] 李永宏,于洪志,孔江平.藏语连续语音语料库设计与实现 [J].计算机工程与应用,2010,46(13):233-235+248.
[4] 杨辰雨.语音合成音库自动标注方法研究 [D].合肥:中国科学技术大学,2014.
[5] 李立永,张连海,冯志远.基于语谱能量的音素边界检测 [J].太赫兹科学与电子信息学报,2013,11(6):936-941.
作者简介:李学林(1990.02-),男,汉族,贵州湄潭人,实验室管理员,实验师,硕士研究生,研究方向:风险管理与统计决策。